贪心
时间复杂度$O(n)$
空间复杂度$O(1)$
1 | class Solution { |
时间复杂度$O(n)$
空间复杂度$O(1)$
1 | class Solution { |
时间复杂度 $O(m+n)$
空间复杂度 $O(1)$
1 | class Solution { |
把新数组想象成一个栈,用一个指针维护栈顶位置
时间复杂度$O(n)$
空间复杂度$O(1)$
1 | class Solution { |
在k8s集群上利用nfs实现跨节点目录共享,部署ollama和nginx作为练习。
环境为openeuler22.03 sp3,k8s1.23.6,docker为容器引擎,flannel提供通信支持
一主(node0-192.168.195.40)二从(node1-192.168.195.41、node2-192.168.195.42)
所有数据利用nfs实现共享(所有节点均需安装nfs服务),数据存储在主节点/opt/k8s_store/目录。分别为/opt/k8s_store/ollama和/opt/k8s_store/nginx
安装NFS服务(所有节点):
1 | sudo dnf install nfs-utils |
编辑/etc/exports文件,添加共享目录配置(存储节点):
1 | /opt/k8s_store *(rw,sync,no_root_squash,no_subtree_check) |
这会使/opt/k8s_store目录对所有节点(*表示所有)可读写。
重启NFS服务:
1 | sudo systemctl restart nfs-server |
1 | [root@node0 ollama]# ls |
配置文件pv.yaml
1 | [root@node0 ollama]# cat pv.yaml |
配置文件pvc.yaml
1 | [root@node0 ollama]# cat pvc.yaml |
配置文件deployment.yaml
1 | [root@node0 ollama]# cat deployment.yaml |
配置文件service.yaml
1 | [root@node0 ollama]# cat service.yaml |
(实际上在本示例中并未进一步使用此处开放的端口),这里可以进一步与dify等工具联动,实现外部api访问服务。可以查阅
Private Deployment of Ollama + DeepSeek + Dify: Build Your Own AI Assistant | Dify
利如下命令进行部署
1 | kubectl apply -f pv.yaml |
最终结果为
1 | [root@node0 ollama]# kubectl get pods |
此处进入pod内部,下载deepseekr1:1.5b完整部署结果
1 | [root@node0 ollama]# kubectl exec -it ollama-deployment-777b9bccb7-sj7wd -- /bin/bash |
可以顺利使用,部署成功。
此处准备了wireshark的本地用户手册作为服务内容。
1 | WiresharkUser'sGuide.zip # 内含n多html文档 |
解压到/opt/k8s_store/nginx/index里面。
1 | unzip "WiresharkUser'sGuide.zip" -d /opt/k8s_store/nginx/index |
在共享目录写一个index.html放在/opt/k8s_store/nginx
1 | [root@node0 nginx]# nano index.html |
用到的配置文件
1 | [root@node0 nginx]# ls |
pv.yaml
1 | [root@node0 nginx]# cat pv.yaml |
pvc.yaml
1 | [root@node0 nginx]# cat pvc.yaml |
nginx-deployment.yaml
1 | [root@node0 nginx]# cat nginx-deployment.yaml |
nginx-service.yaml
1 | [root@node0 nginx]# cat nginx-service.yaml |
应用即可
所有人可以访问
1 | [root@node0 nginx]# sudo chmod -R 777 /opt/k8s_store |
如果之前部署文件有误要重新部署,可以使用删除原配置重新部署
1 | # 删除旧的pvc和pv创建新的 |
显示
1 | [root@node0 ~]# kubectl get pvc ollama-pvc |
当PVC显示为Terminating时,通常意味着Kubernetes正在执行删除操作,但未能完全完成。这通常是由于某些资源清理不完整或在删除过程中发生阻塞。
查看该PVC详细信息
1 | kubectl describe pvc ollama-pvc |
此处显示
1 | [root@node0 ~]# kubectl describe pvc ollama-pvc |
可以看到,它正处于Finalizers保护机制下。Finalizers: [kubernetes.io/pvc-protection]表示Kubernetes正在确保该PVC不会在被使用时被删除。
由于ollama-deployment-777b9bccb7-wq6lh这个Pod仍在使用该PVC,删除操作没有完成。
解决方案为删除Pod
1 | kubectl delete pod ollama-deployment-777b9bccb7-wq6lh |
这时候pvc即可删除
除此之外,可以选择强制删除pvc,不过不做推荐(此处未使用)
1 | kubectl delete pvc ollama-pvc --force --grace-period=0 |
刚才执行了
1 | kubectl delete pod ollama-deployment-777b9bccb7-wq6lh |
但由于之前部署由Deployment管理,Deployment会自动创建一个新的Pod来替代被删除的Pod。
如下所示
1 | [root@node0 ~]# kubectl get po |
阻止pod自动重启可以删除deployment
1 | kubectl delete deployment ollama-deployment |
重新查看,发现删除成功
1 | [root@node0 ollama]# kubectl get pods |
1 | kubectl scale deployment k8s-nginx --replicas=1 |
1 | PS C:\Users\dd\Desktop> scp '.\WiresharkUser''sGuide.zip' root@192.168.195.40:/opt/k8s_store/nginx |
1 | nano /opt/prometheus/config/prometheus.yml |
填入如下内容作为配置(监控自己)
1 | scrape_configs: |
运行
1 | docker run -d --name=prometheus -p 9090:9090 -v /opt/prometheus/config/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus |
运行成功后可以浏览器访问

1 | docker run -d --name=mynginx -p 10080:80 nginx |
此时可以在浏览器访问

使用stats查看某容器状态
1 | [root@node0 docker.service.d]# docker stats mynginx |
说明 –no-stream Disable streaming stats and only pull the first result\
1 | docker stats --no-stream mynginx | awk 'NR!=1{print $3}' |
解释
NR:表示当前处理的行号。NR != 1 代表跳过第一行(标题行)
print $3:表示输出每行的第三列(即 CPU 使用百分比)。
awk 是一种强大的文本处理工具,通常用于从文本中提取、处理和生成报告。它特别适用于处理结构化的文本数据,比如日志文件、CSV 文件、配置文件、表格数据等。它可以按行处理文本,并且可以通过分隔符(例如空格、逗号等)来处理数据。
awk 基本用途和功能
awk 可以轻松处理按空格或其他分隔符(例如逗号)分隔的文本。默认情况下,awk 使用空格或制表符(Tab)作为分隔符来划分每行数据,并通过 $1, $2, $3 等来访问每一列。
示例:从一个文件或命令输出中提取每行的第一列数据:
1 | echo -e "apple 10\nbanana 20" | awk '{print $1}' |
输出:
1 | apple |
在 awk 中使用条件语句、循环、数学运算等来处理文本中的数据。
示例:计算每行第一列和第二列的和:
1 | echo -e "10 20\n30 40" | awk '{print $1 + $2}' |
输出:
1 | 30 |
可以指定自定义的字段分隔符。例如,当数据是 CSV 格式时,分隔符是逗号。
示例:指定逗号作为分隔符来处理 CSV 数据:
1 | echo -e "apple,10\nbanana,20" | awk -F ',' '{print $1}' |
输出:
输出:
1 | apple |
awk 允许根据条件执行特定的操作,例如打印满足条件的行。
示例:打印包含“banana”这一单词的行:
1 | echo -e "apple 10\nbanana 20" | awk '$1 == "banana" {print $0}' |
输出:
1 | banana 20 |
awk 提供了一些内置变量,比如:
NR:当前处理的行号。
NF:当前行的字段数。
$0:整行文本。
$1, $2, $3:每行的第 1、2、3 列。
FS:字段分隔符(默认是空格或制表符)。
打印格式化输出
awk 可以自定义输出格式,比如指定列宽、对齐等。
示例:输出每个字段的固定宽度:
1 | echo -e "apple 10\nbanana 20" | awk '{printf "%-10s %10s\n", $1, $2}' |
输出:
1 | apple 10 |
安装
1 | docker run -d --volume=/:/rootfs:ro \ |
此时可以在8080访问
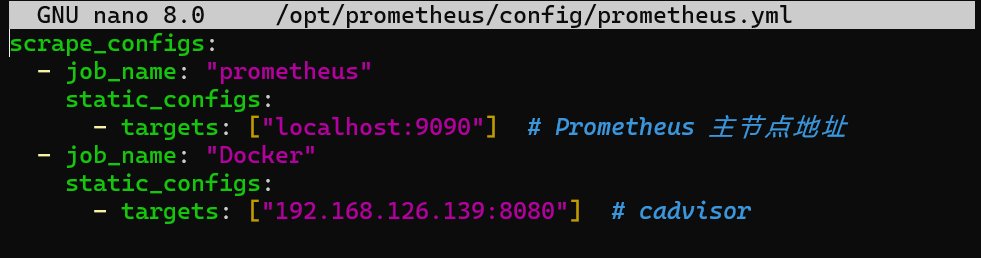
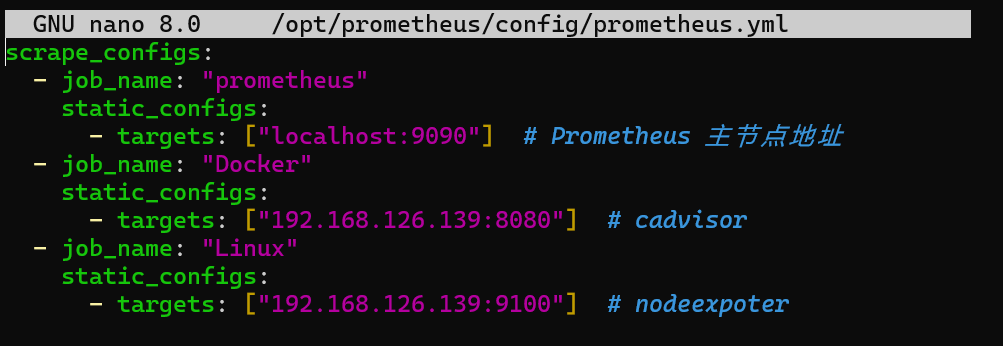
在prometheus绑定的配置文件添加监控源
1 | nano /opt/prometheus/config/prometheus.yml |
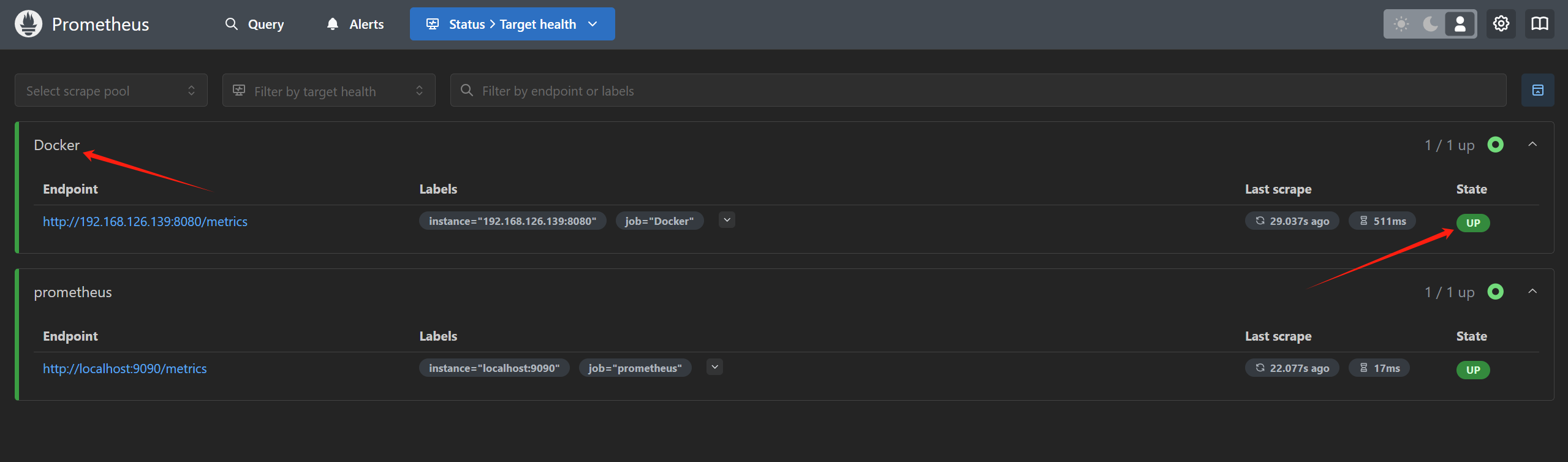
重启prometheus
1 | docker restart prometheus |
静待片刻即可收到返回的新数据
1 | docker run -d --name=grafana -p 3000:3000 grafana/grafana |
之后可以在端口3000访问
默认账号密码
1 | admin |
第一次会提示修改密码
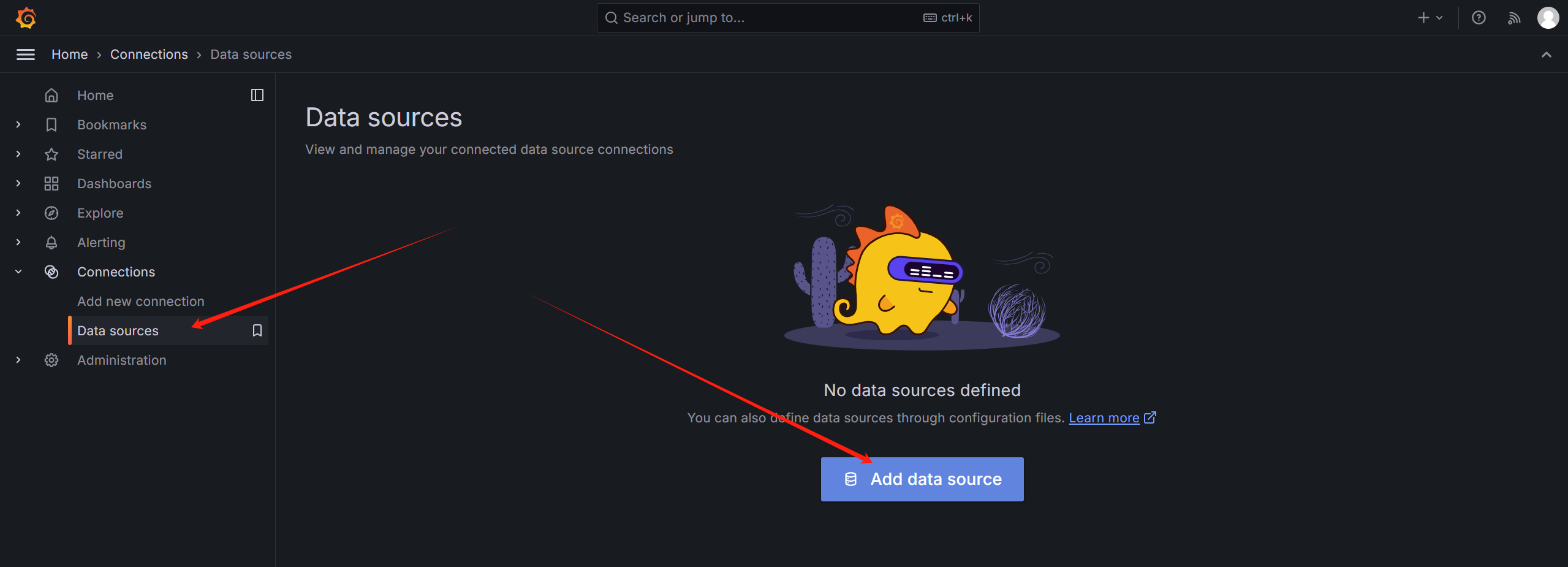
先添加数据源
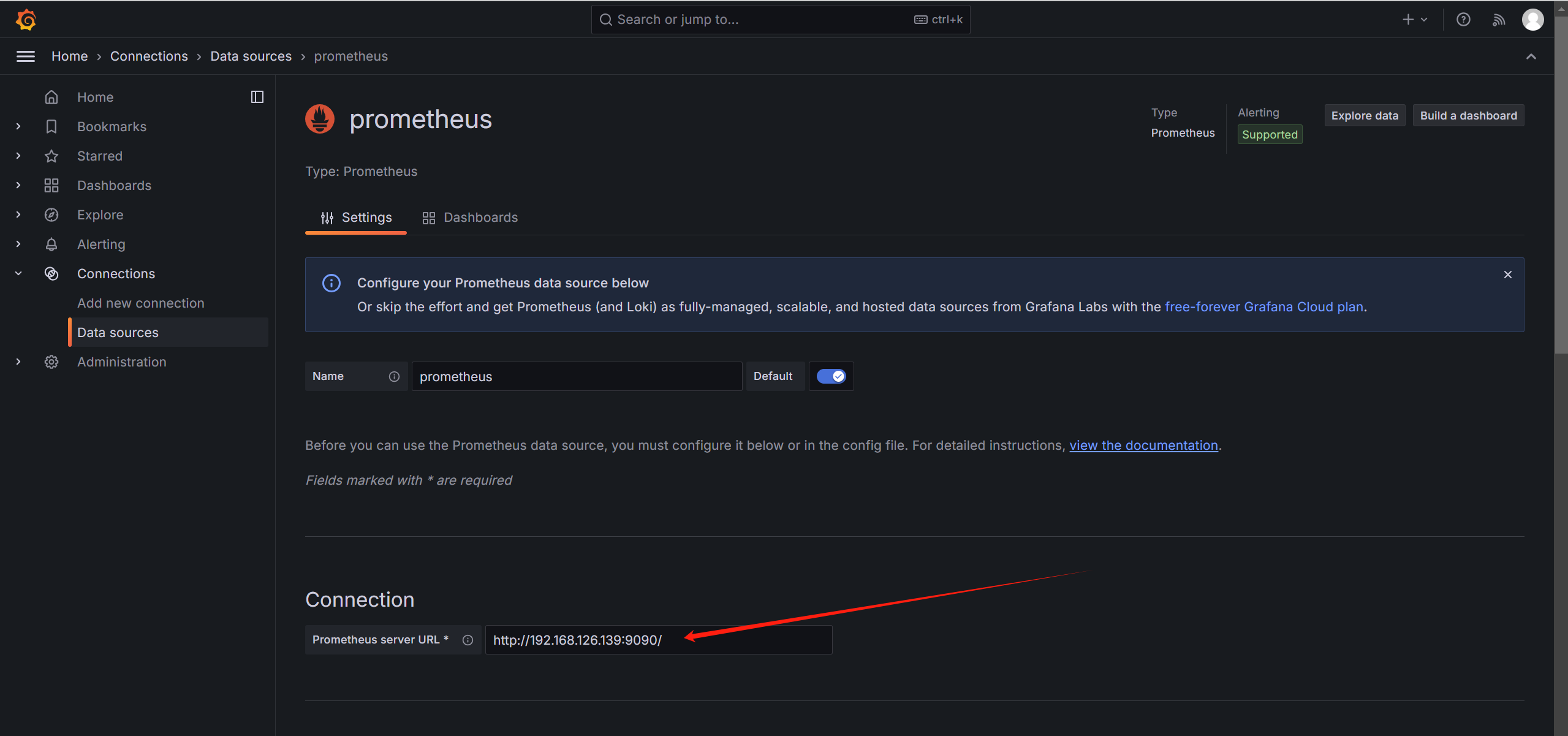
再导入监控模板
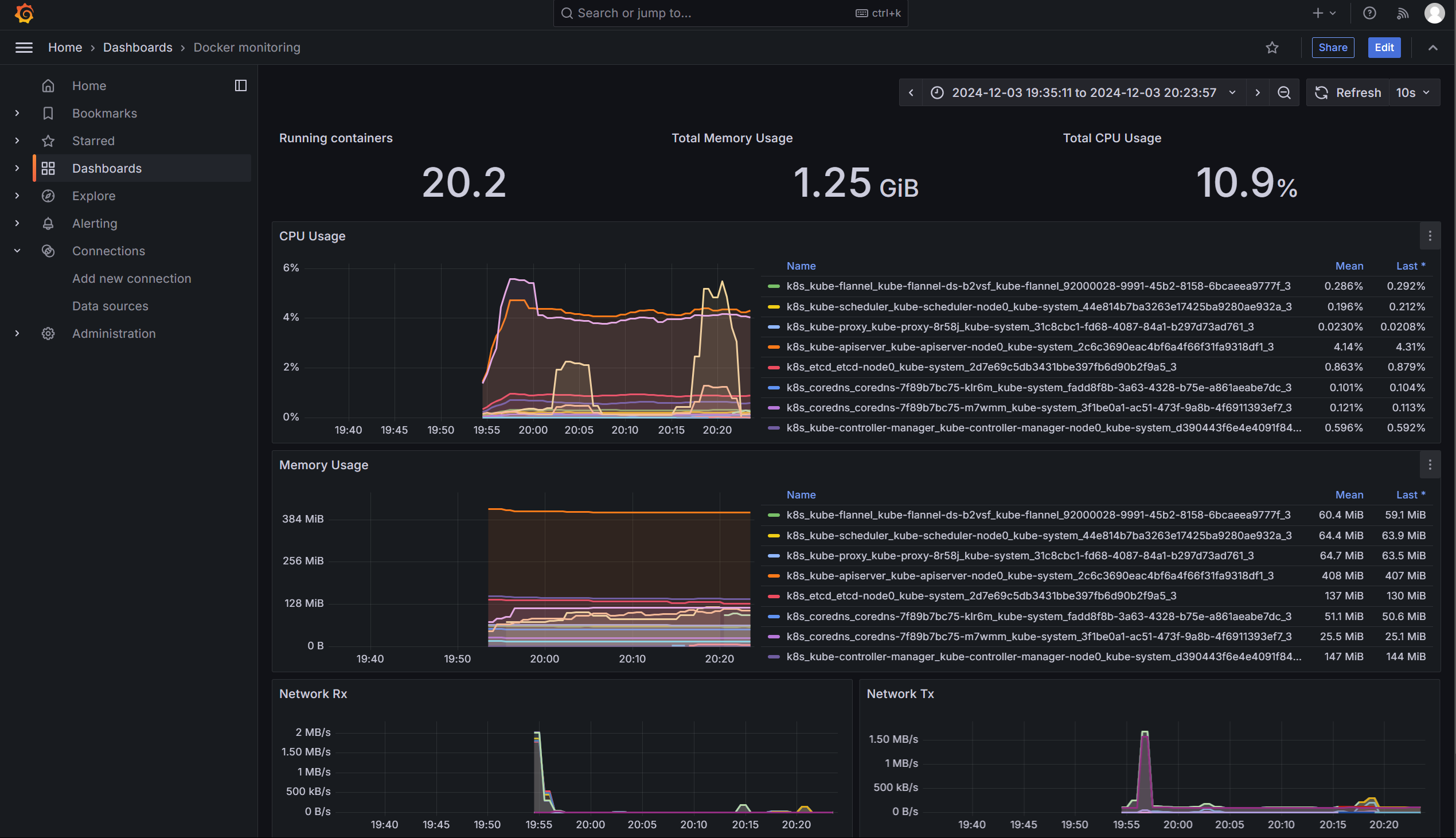
之后即可看到监控数据
先创建容器,使用 –net=”host”` 网络模式共享主机网络堆栈,不需要-p进行端口映射
1 | docker run -d --name=node-exporter --net="host" --pid="host" -v "/:/host:ro,rslave" quay.io/prometheus/node-exporter:latest --path.rootfs=/host |
1 | nano /opt/prometheus/config/prometheus.yml |
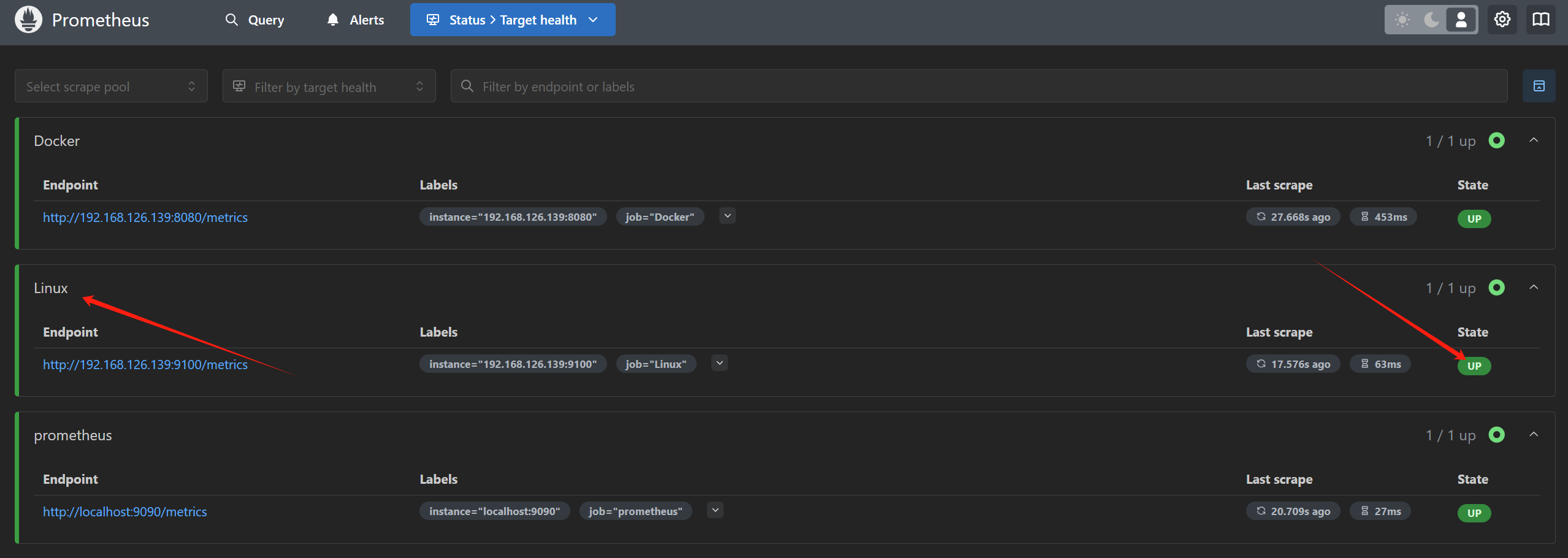
1 | docker restart prometheus |
静待一会即可
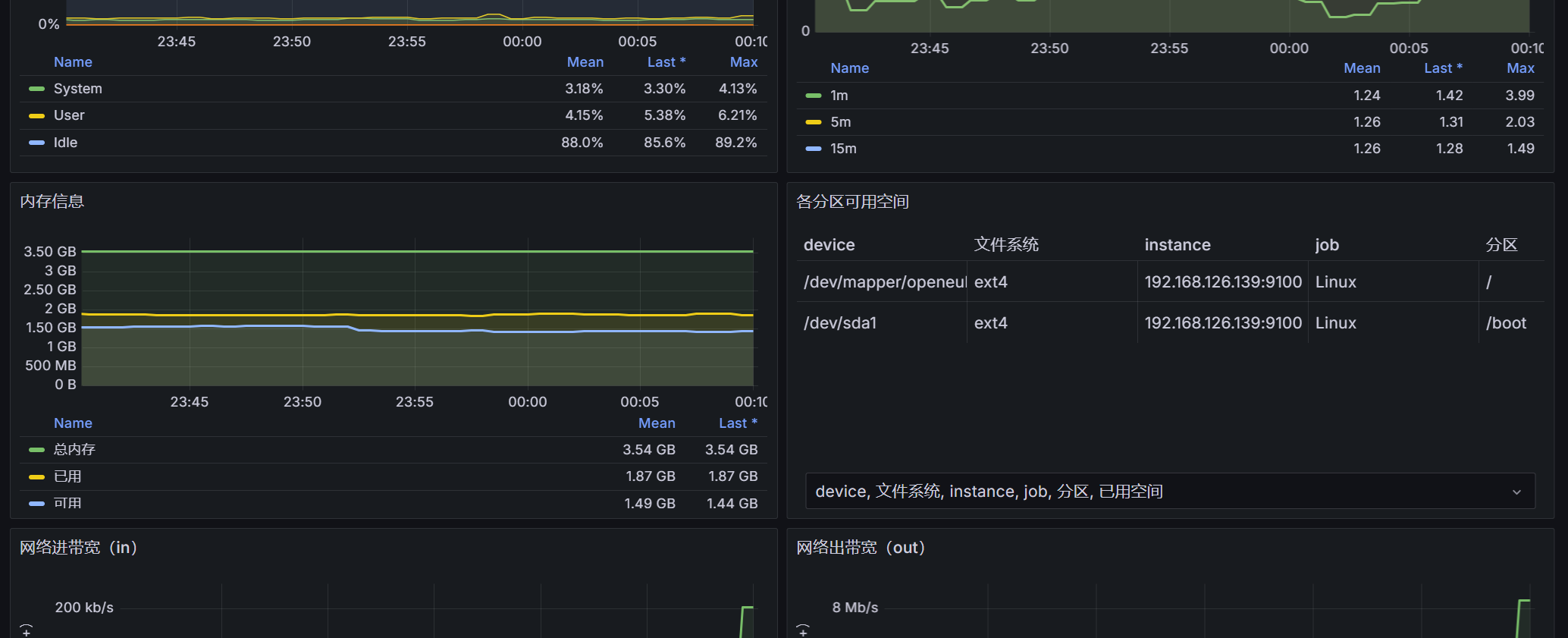
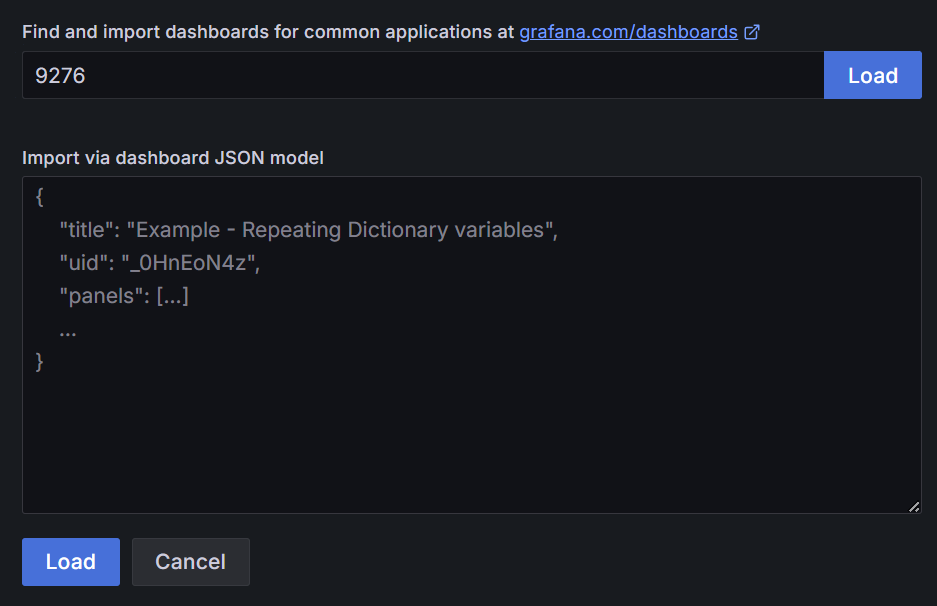
对于Grafana,依旧是带入库模板,编号9276
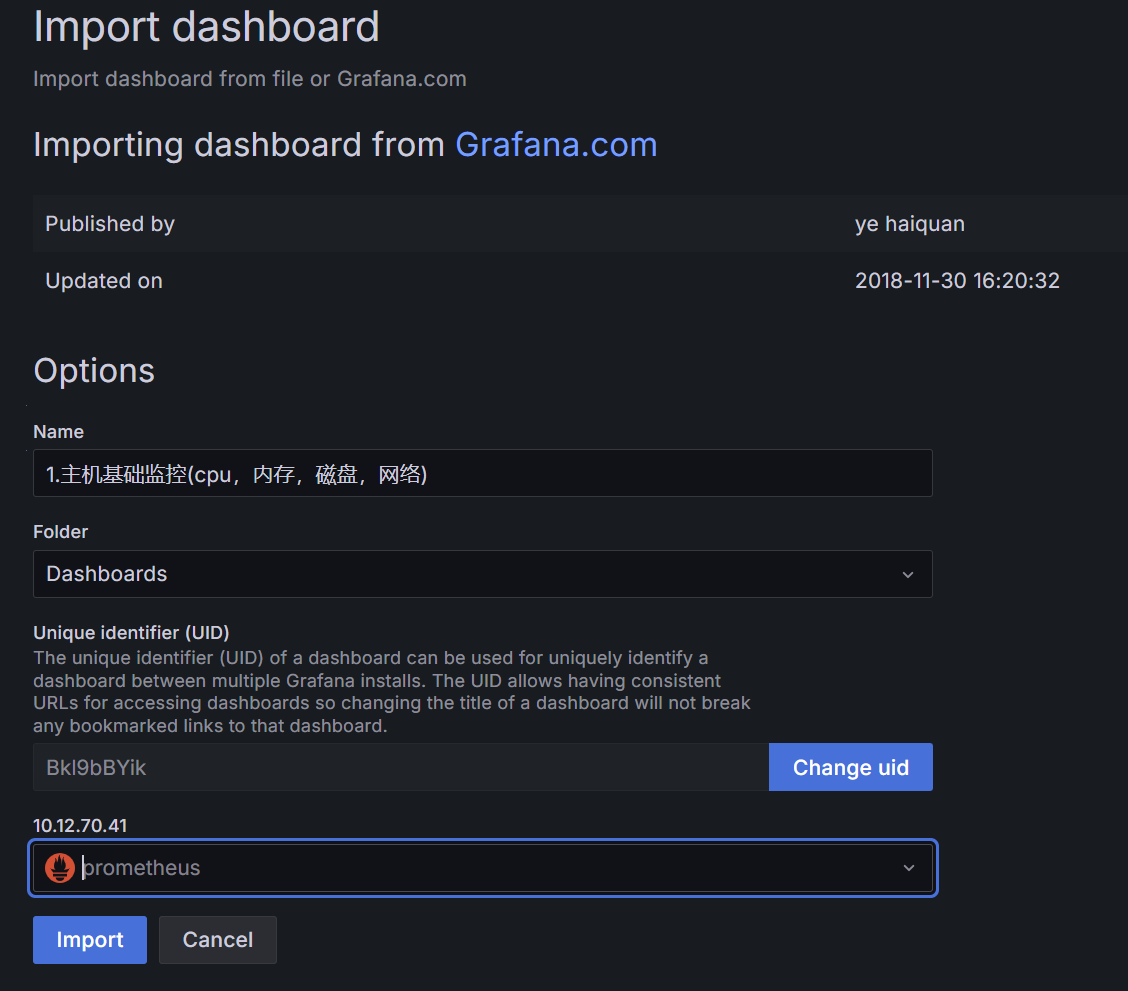
之后即可看到面板
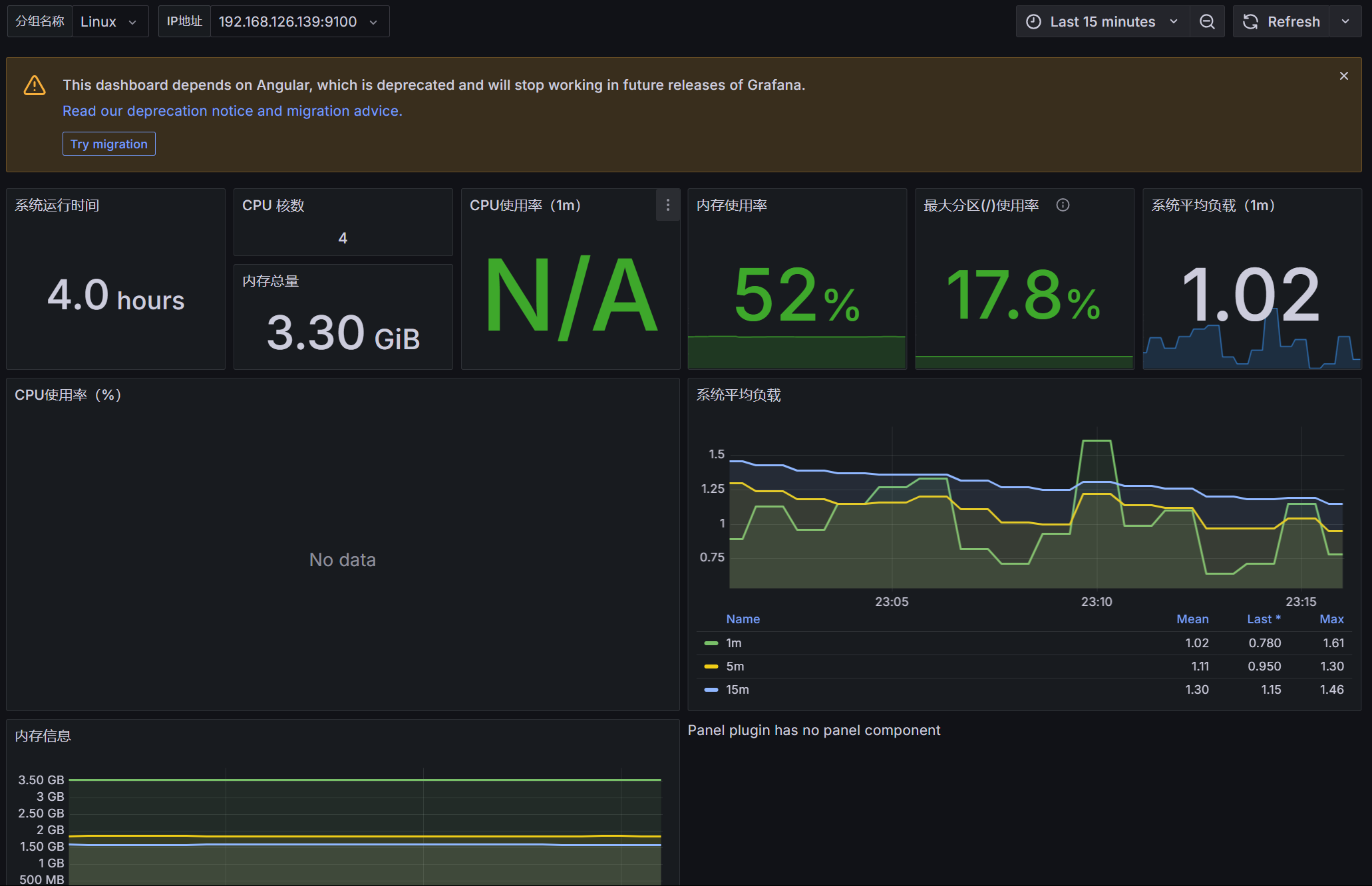
有些显示没有图表,一般是三个原因
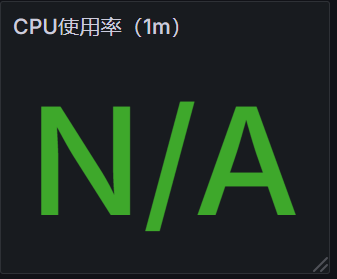
有结果的
1 | node_cpu_seconds_total{instance=~"$node",mode="idle"} |
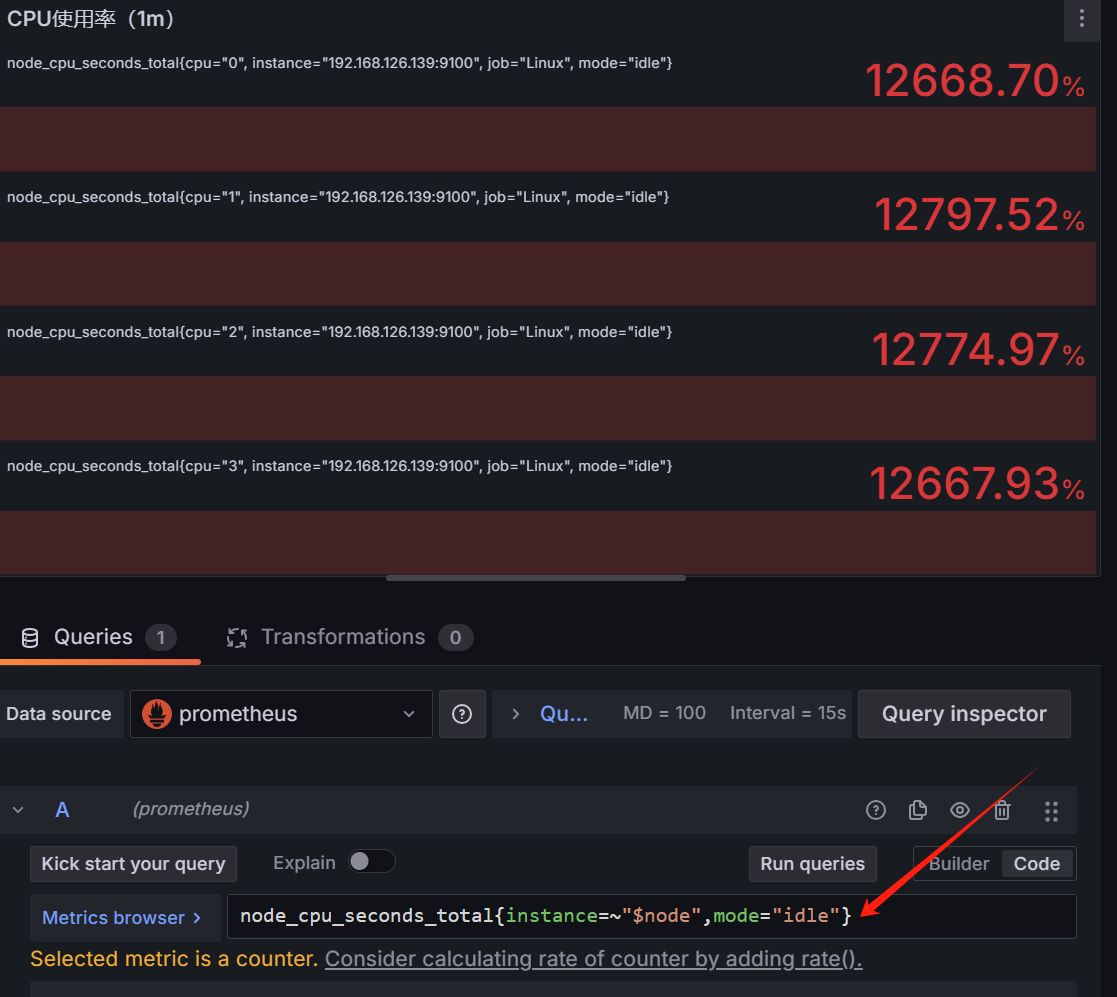
加一个irate就没了
1 | irate(node_cpu_seconds_total{instance=~"$node",mode="idle"}[1m]) |
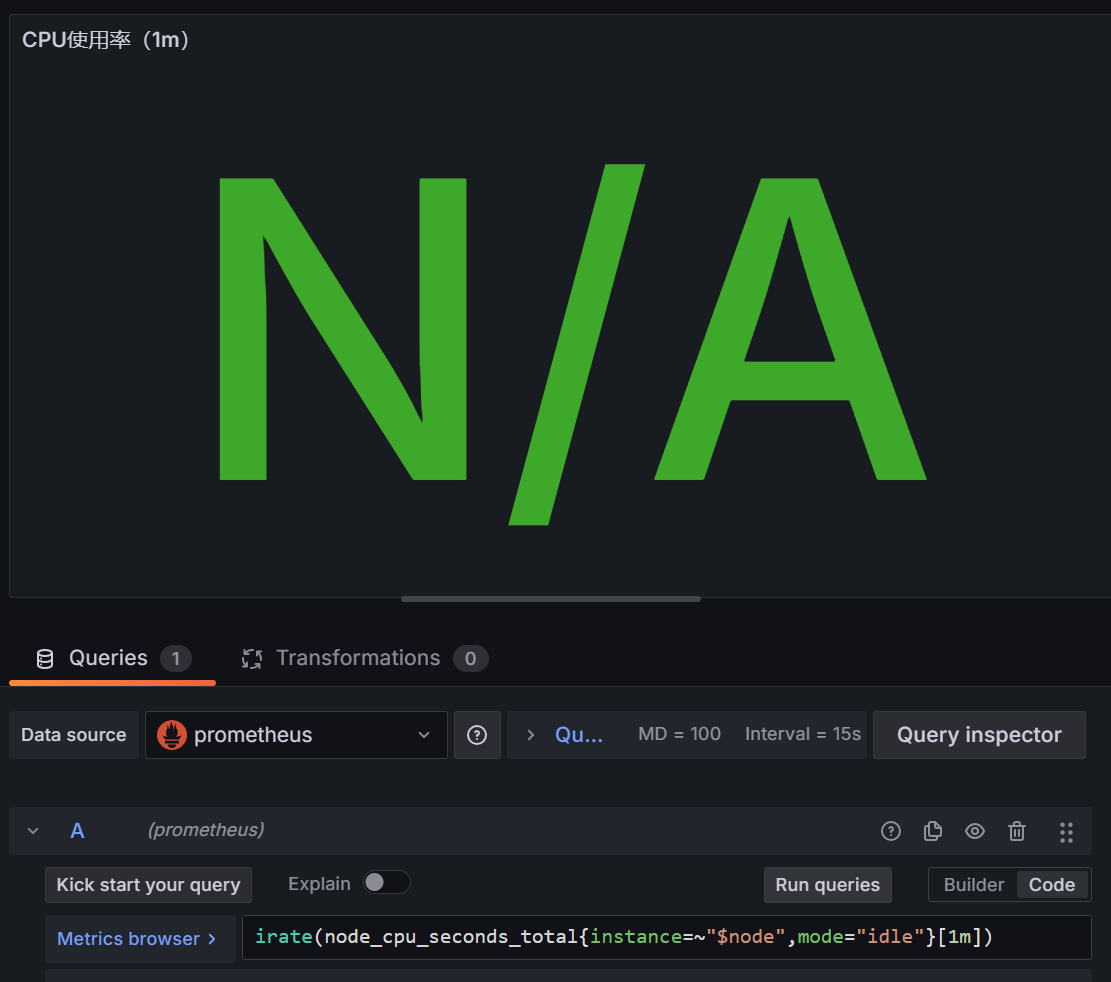
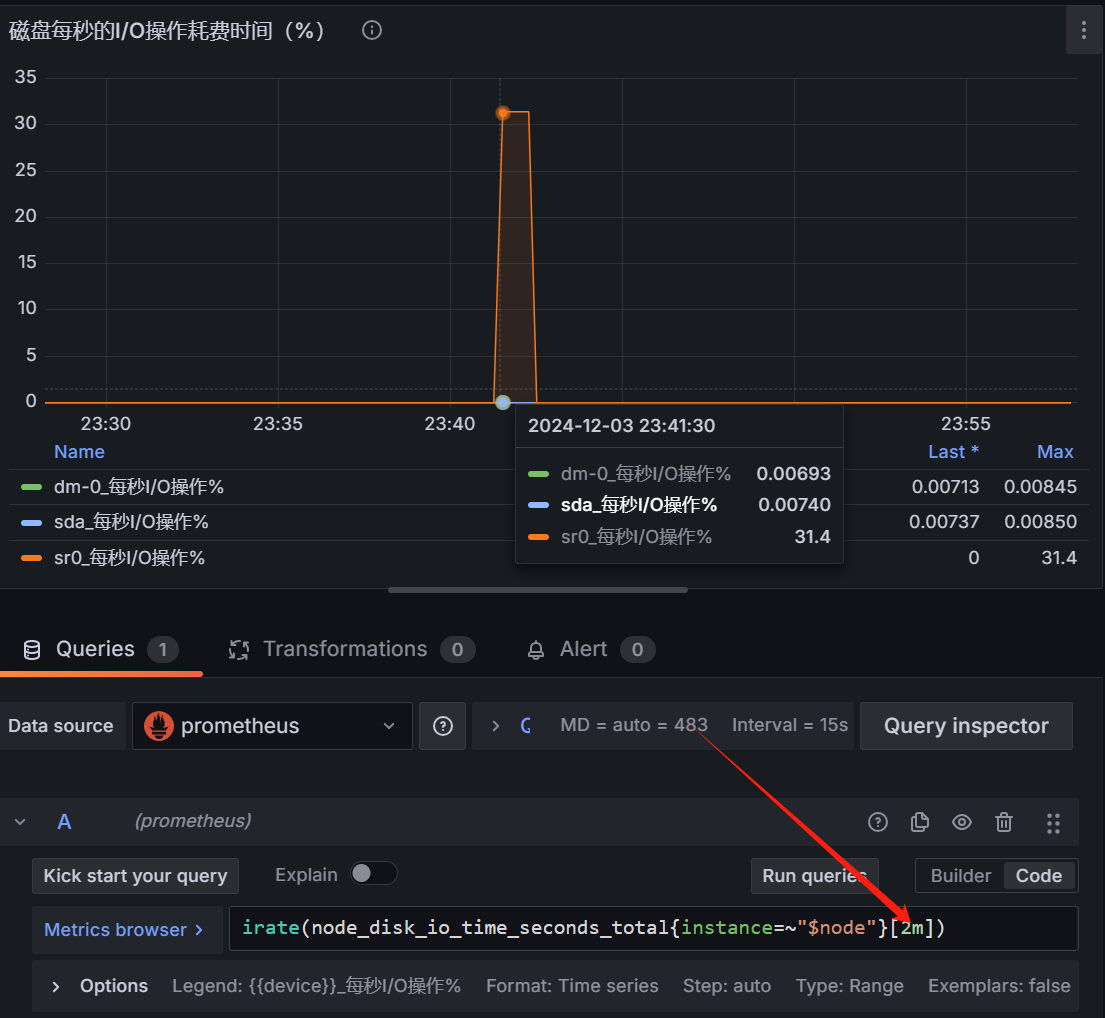
推测node_cpu_seconds_total 只被更新不频繁,增加时间范围,到2分钟,可以
1 | irate(node_cpu_seconds_total{instance=~"$node",mode="idle"}[2m]) |
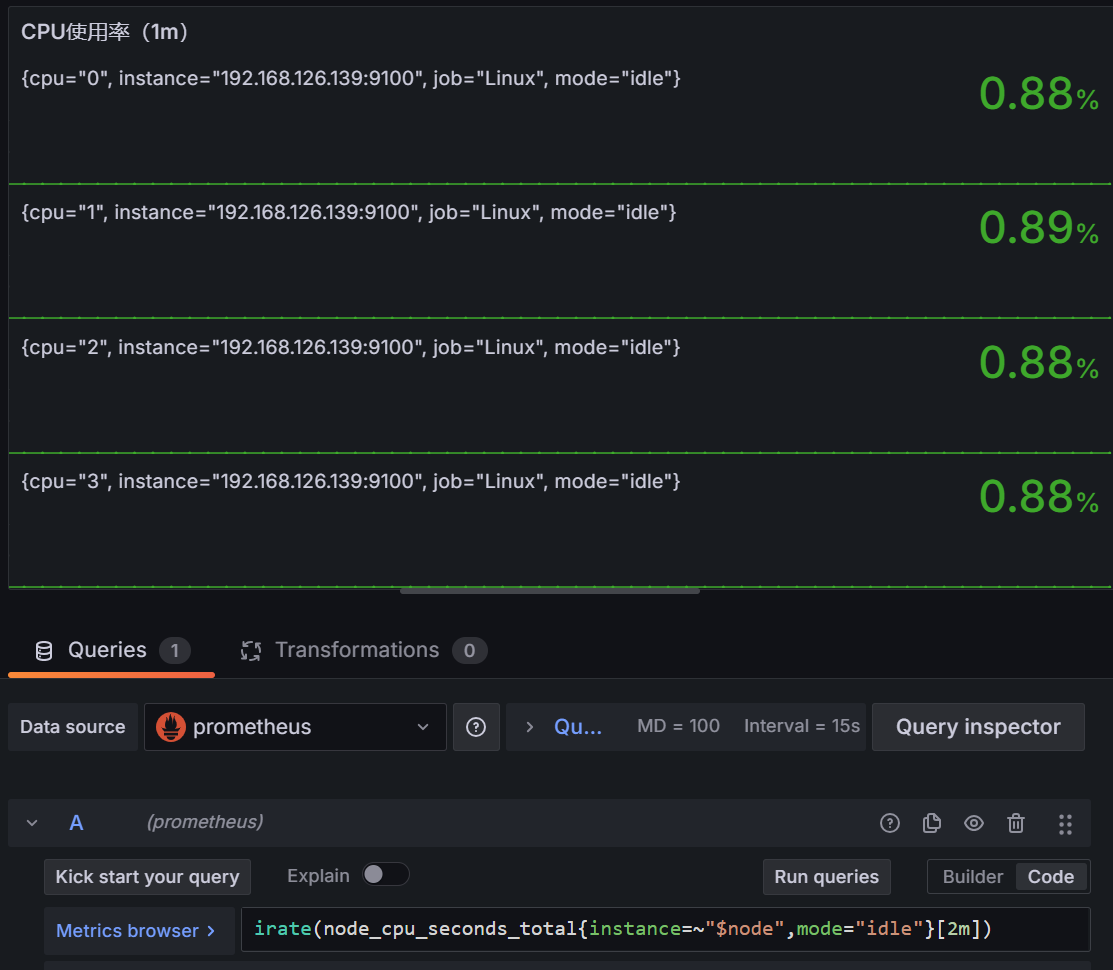
于是问题解决
1 | 100 - (avg(irate(node_cpu_seconds_total{instance=~"$node",mode="idle"}[2m])) * 100) |
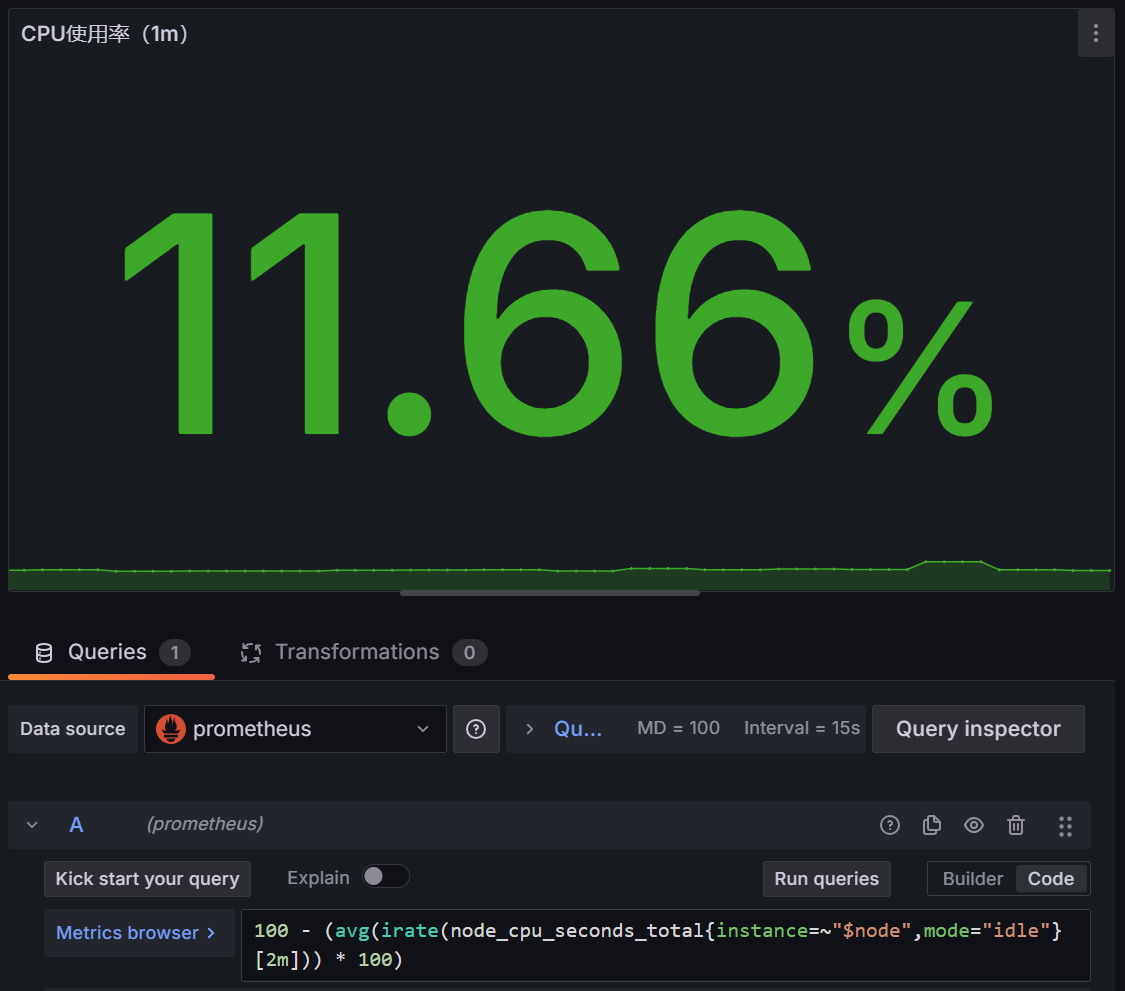
点进去发现具有同样的问题,时间片从1m改为2m解决,最后一个为实时io,无data,查询普罗米修斯,返回状态码0
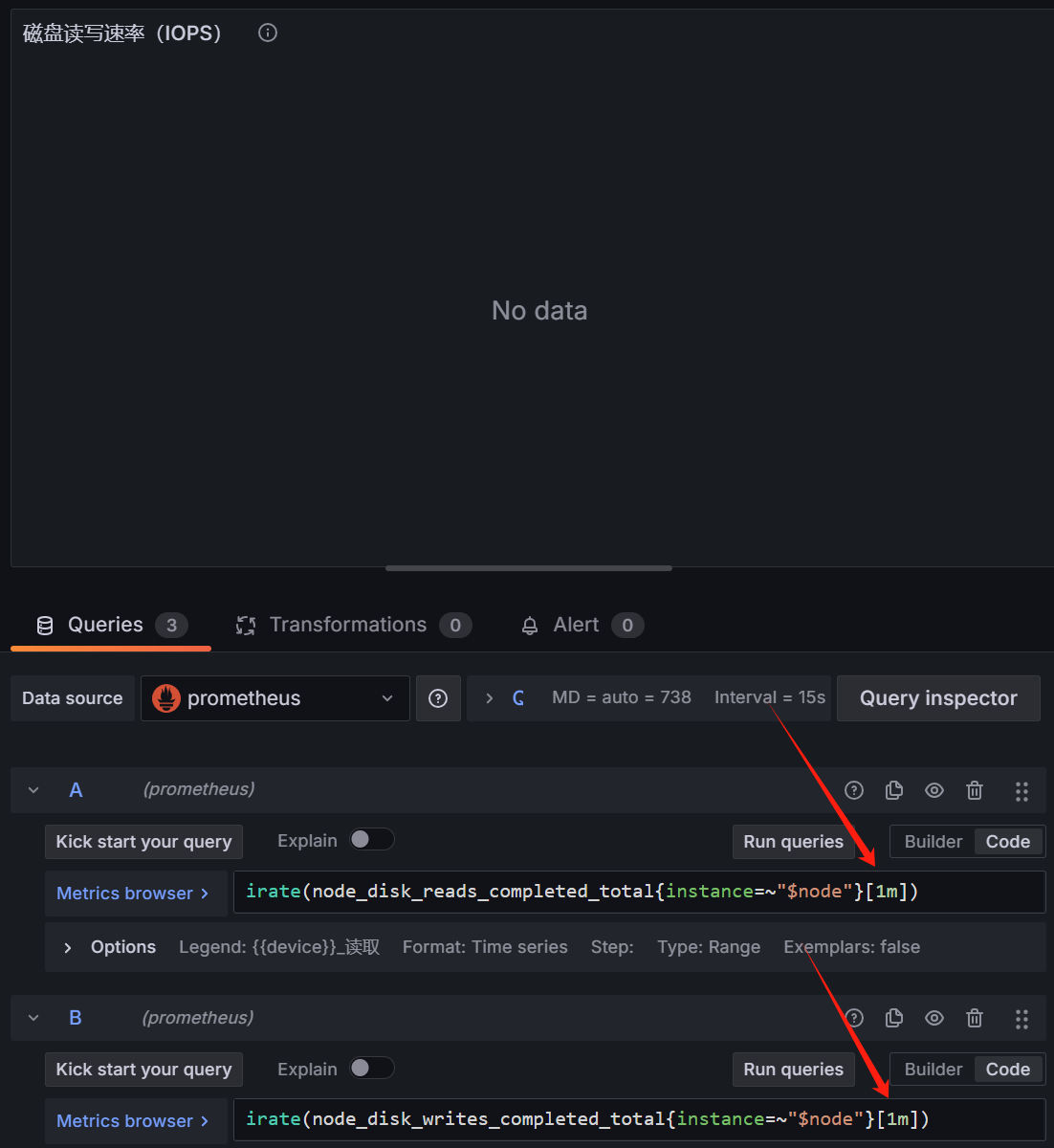
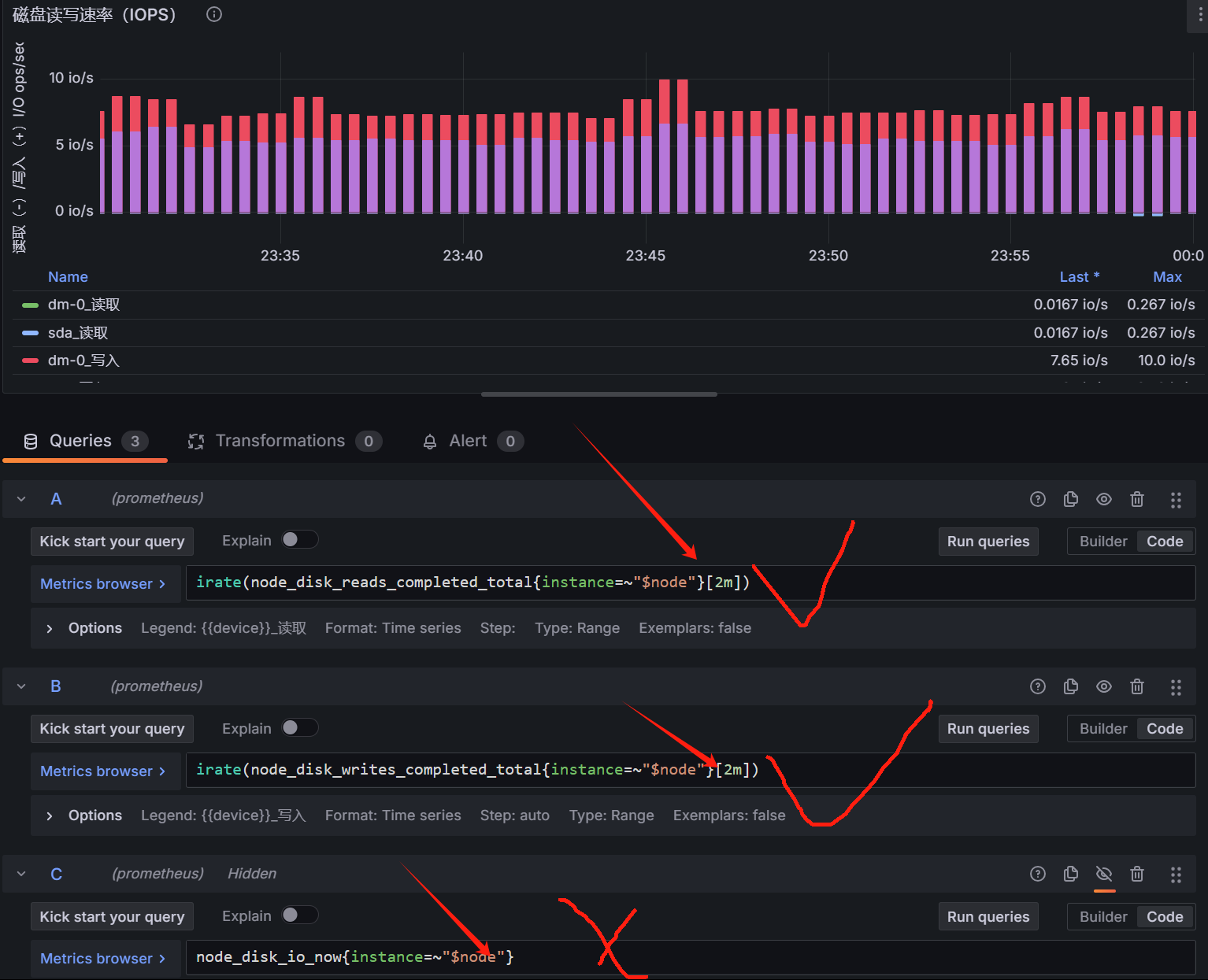
与上面类似处理
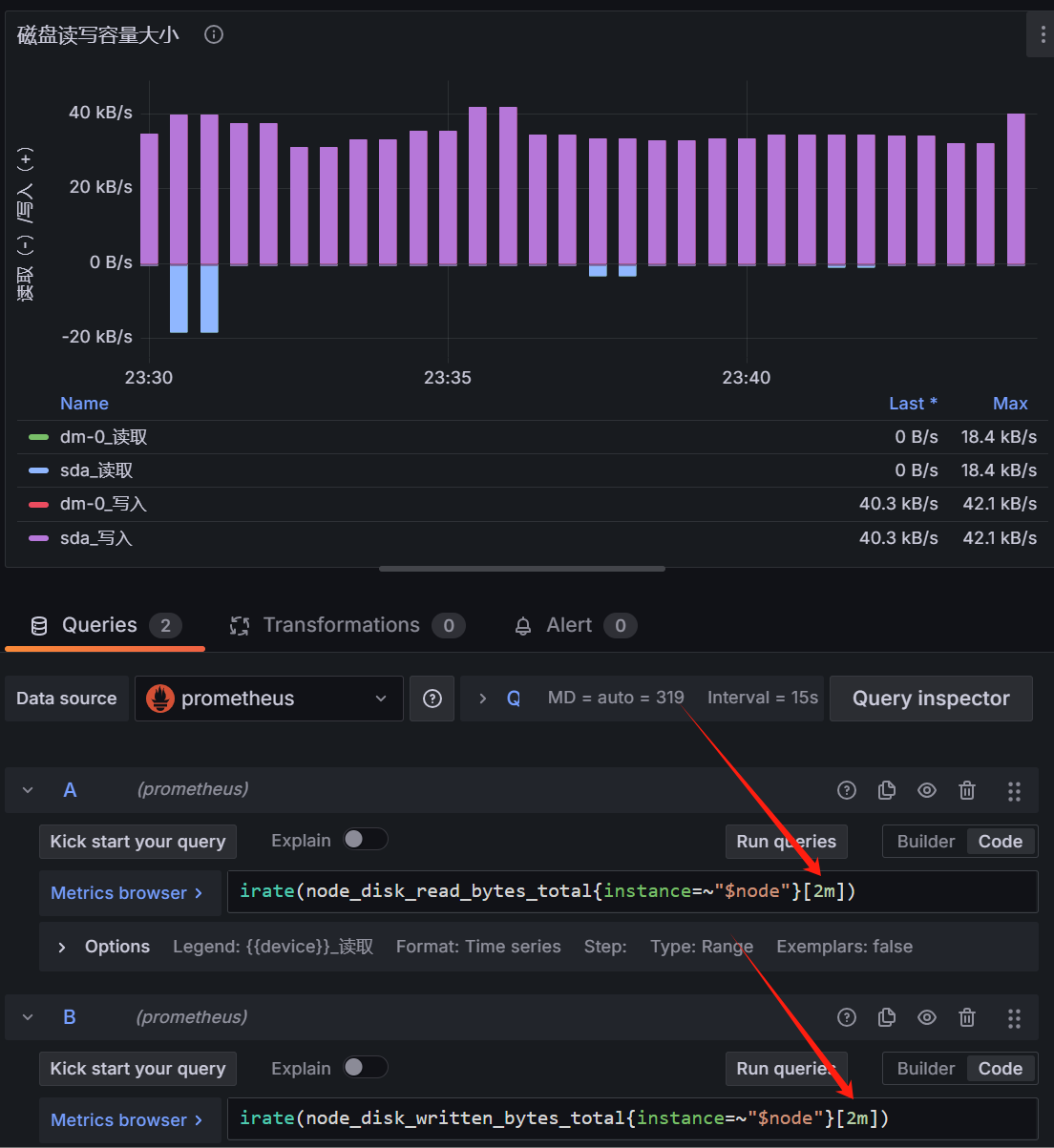
类似处理,可以显示数据(实际上四条查询,前两个指标nodata,原因尚不清楚,后两个有)
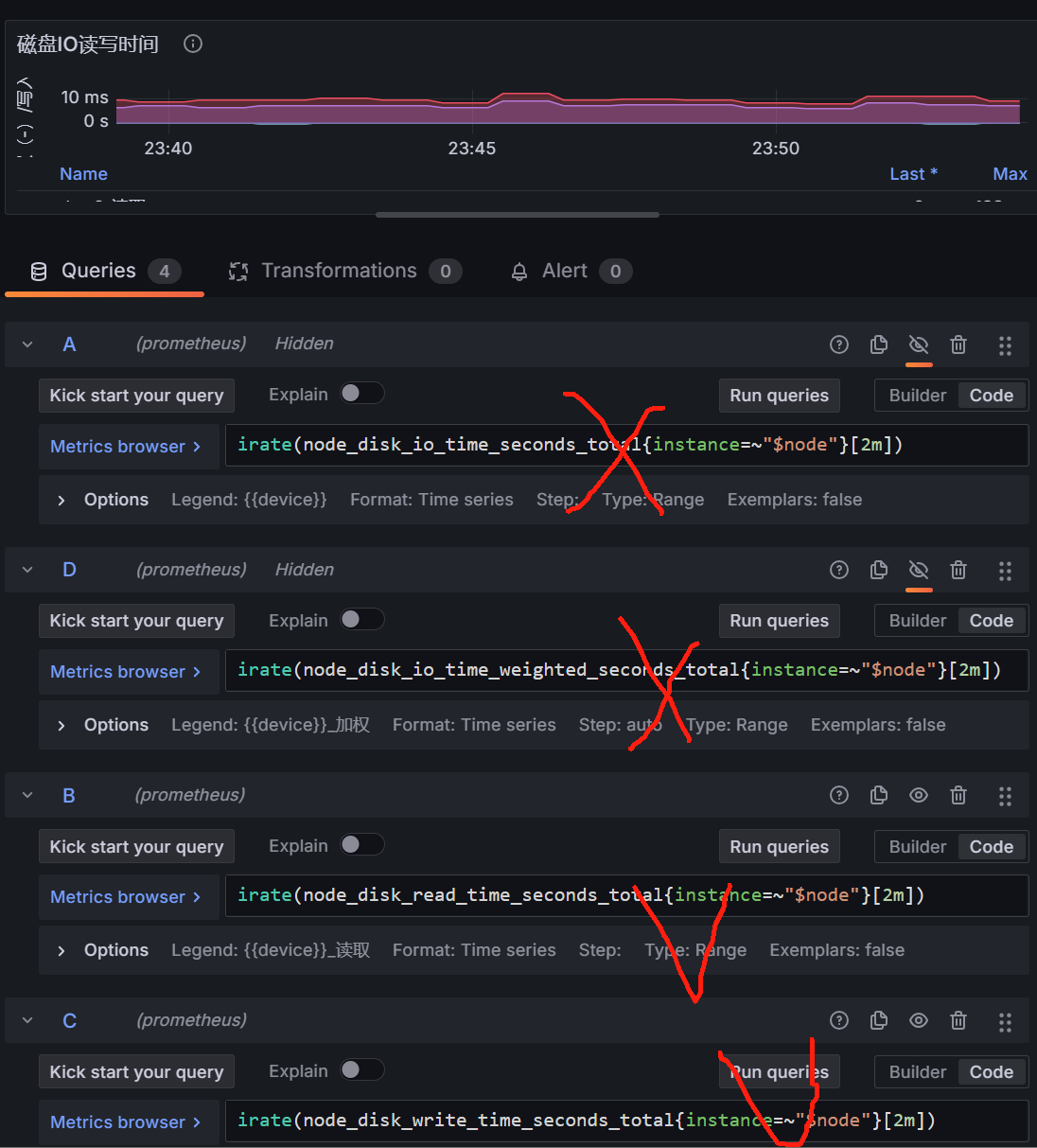
类似处理,解决
比如下面这个是默认的网卡名称不对
1 | irate(node_network_receive_bytes_total{instance=~'$node',device=~'$nic'}[5m])*8 |
改为实际的网卡即可
1 | irate(node_network_receive_bytes_total{instance=~'$node',device=~'ens33'}[5m])*8 |
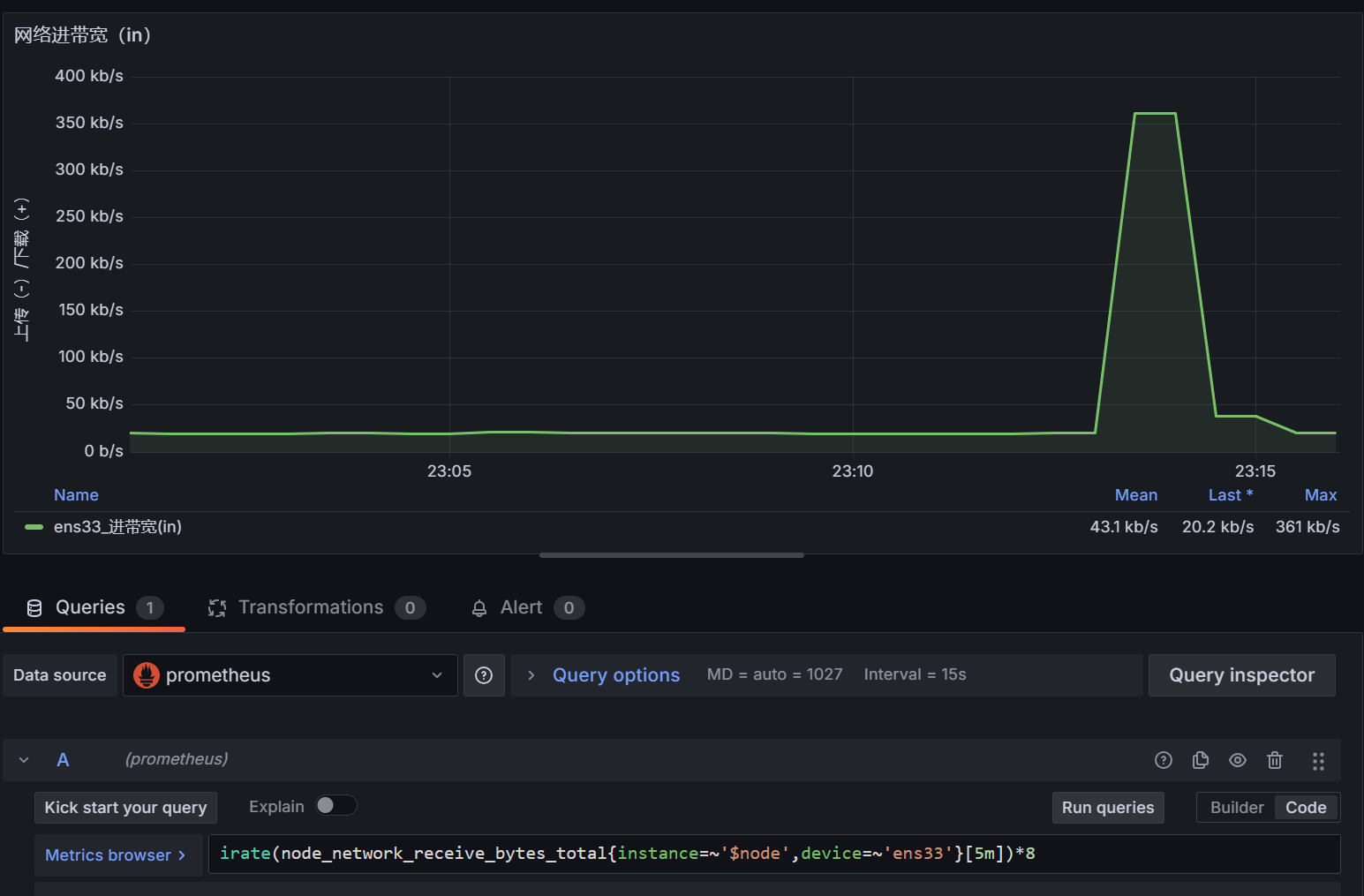
刷新解决